Learning by Correction: Efficient Tuning Task for Zero-Shot Generative Vision-Language Reasoning
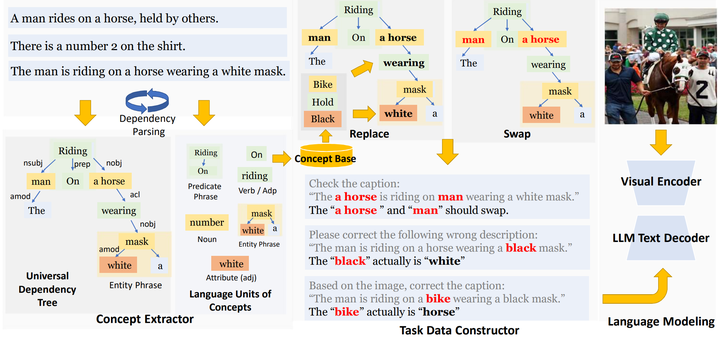 Illustration of the overall pipeline of ICCC. The concept extractor parses the sentence to obtain linguistic units of concepts. The task data constructor aims to produce the sample according to the sentence structure with the “replace” and “swap” operations. Finally, the generated ICCC data is used for image-to-text generative training for VLMs.
Illustration of the overall pipeline of ICCC. The concept extractor parses the sentence to obtain linguistic units of concepts. The task data constructor aims to produce the sample according to the sentence structure with the “replace” and “swap” operations. Finally, the generated ICCC data is used for image-to-text generative training for VLMs.
Abstract
Generative vision-language models (VLMs) have shown impressive performance in zero-shot vision-language tasks like image captioning and visual question answering. However, improving their zero-shot reasoning typically requires second-stage instruction tuning, which relies heavily on human-labeled or large language model-generated annotation, incurring high labeling costs. To tackle this challenge, we introduce Image-Conditioned Caption Correction (ICCC), a novel pre-training task designed to enhance VLMs’ zero-shot performance without the need for labeled task-aware data. The ICCC task compels VLMs to rectify mismatches between visual and language concepts, thereby enhancing instruction following and text generation conditioned on visual inputs. Leveraging language structure and a lightweight dependency parser, we construct data samples of ICCC task from image-text datasets with low labeling and computation costs. Experimental results on BLIP2 and InstructBLIP demonstrate significant improvements in zero-shot image-text generation-based VL tasks through ICCC instruction tuning.
Rongjie Li
PhD Students
My research interests include scene understanding, deep learning, graph neural networks.
Yu Wu
Master Student
My research interests include visual reasoning, multi-modal learning and explainable AI.
Xuming He
Associate Professor
My research interests include few/low-shot learning, graph neural networks and video understanding.