Mining Fine-Grained Image-Text Alignment for Zero-Shot Captioning via Text-Only Training
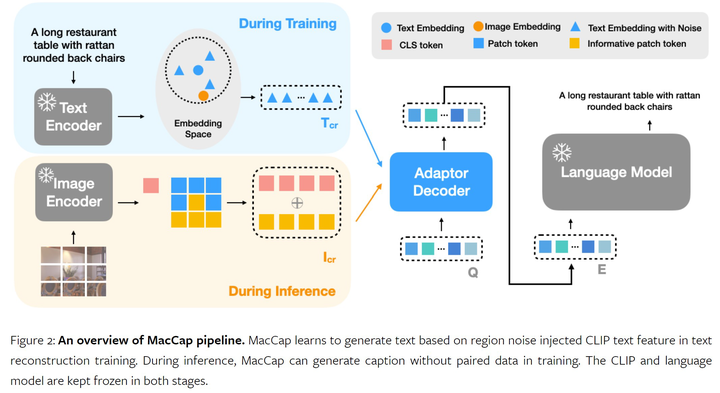 MacCap learns to generate text based on region noise injected CLIP text feature in text reconstruction training. During inference, MacCap can generate caption without paired data in training. The CLIP and language model are kept frozen in both stages.
MacCap learns to generate text based on region noise injected CLIP text feature in text reconstruction training. During inference, MacCap can generate caption without paired data in training. The CLIP and language model are kept frozen in both stages.
Abstract
MacCap introduces a novel zero-shot image captioning framework with text-only training by noise injection training and visual subregion aggregation. It leverages the fine-grained visual alignments from multimodal embedding space, achieving an efficient zero shot captioning. MacCap improves zero-shot captioning performance over popular captioning benchmarks under various settings.
Type
Publication
In Proceedings of the AAAI Conference on Artificial Intelligence, 2024Proceedings of the AAAI Conference on Artificial Intelligence, 2023