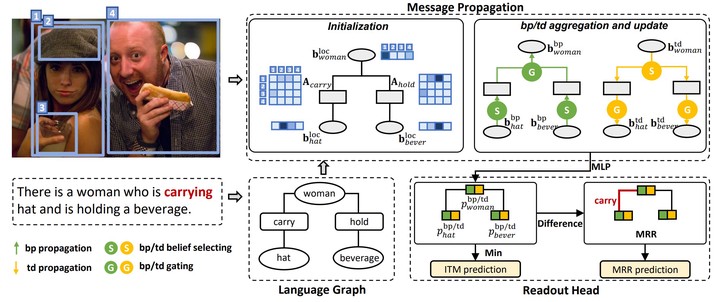
 Given an image and an expression, we first generate visual and linguistic candidates by a detector and a language parser, and compute their representations. Then we use the Context-sensitive Propagation Network to inter alignments between visual-linguistic candidates, which conducts bi-directional message propagation based on the language graph. The propagation initializes the messages by computing local beliefs, selectively aggregates the context information and updates the belief with a context-sensitive gating function. Predictions for this case are obtained by exploiting the beliefs from the propagation. In the language graph, the ellipses represent entity phrases and the rectangles stand for relation phrases. Further elaboration can be found in the main text.
Given an image and an expression, we first generate visual and linguistic candidates by a detector and a language parser, and compute their representations. Then we use the Context-sensitive Propagation Network to inter alignments between visual-linguistic candidates, which conducts bi-directional message propagation based on the language graph. The propagation initializes the messages by computing local beliefs, selectively aggregates the context information and updates the belief with a context-sensitive gating function. Predictions for this case are obtained by exploiting the beliefs from the propagation. In the language graph, the ellipses represent entity phrases and the rectangles stand for relation phrases. Further elaboration can be found in the main text.
Abstract
This paper introduces Grounded Image Text Matching with Mismatched Relation (GITM-MR), a novel visual-linguistic joint task that evaluates the relation understanding capabilities of transformer-based pre-trained models. GITM-MR requires a model to first determine if an expression describes an image, then localize referred objects or ground the mismatched parts of the text. We provide a benchmark for evaluating vision-language (VL) models on this task, with a focus on the challenging settings of limited training data and out-of-distribution sentence lengths. Our evaluation demonstrates that pre-trained VL models often lack data efficiency and length generalization ability. To address this, we propose the Relation-sensitive Correspondence Reasoning Network (RCRN), which incorporates relation-aware reasoning via bi-directional message propagation guided by language structure. Our RCRN can be interpreted as a modular program and delivers strong performance in terms of both length generalization and data efficiency.