 Given an ambiguous image as input, our model consists of several expert networks and a gating network and produces segmentation samples with corresponding weights. It represents the aleatoric uncertainty at two granularity levels, (e.g. the input image can be annotated as either “2” or “3” and also has variations near boundaries.) and is trained by an Optimal-Transport-based loss function which minimizes the distance between the MoSE outputs and ground truth annotations.
Given an ambiguous image as input, our model consists of several expert networks and a gating network and produces segmentation samples with corresponding weights. It represents the aleatoric uncertainty at two granularity levels, (e.g. the input image can be annotated as either “2” or “3” and also has variations near boundaries.) and is trained by an Optimal-Transport-based loss function which minimizes the distance between the MoSE outputs and ground truth annotations.
Abstract
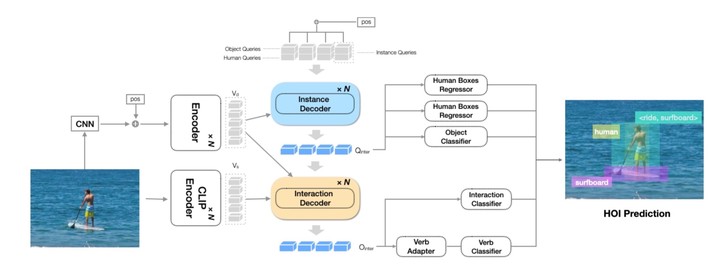
Human-Object Interaction (HOI) detection aims to localize human-object pairs and recognize their interactions. Recently, Contrastive Language-Image Pre-training (CLIP) has shown great potential in providing interaction prior for HOI detectors via knowledge distillation. However, such approaches often rely on large-scale training data and suffer from inferior performance under few/zero-shot scenarios. In this paper, we propose a novel HOI detection framework that efficiently extracts prior knowledge from CLIP and achieves better generalization. In detail, we first introduce a novel interaction decoder to extract informative regions in the visual feature map of CLIP via a cross-attention mechanism, which is then fused with the detection backbone by a knowledge integration block for more accurate human-object pair detection. In addition, prior knowledge in CLIP text encoder is leveraged to generate a classifier by embedding HOI descriptions. To distinguish fine-grained interactions, we build a verb classifier from training data via visual semantic arithmetic and a lightweight verb representation adapter. Furthermore, we propose a training-free enhancement to exploit global HOI predictions from CLIP. Extensive experiments demonstrate that our method outperforms the state of the art by a large margin on various settings, eg+ 4.04 mAP on HICO-Det.