 Given an ambiguous image as input, our model consists of several expert networks and a gating network and produces segmentation samples with corresponding weights. It represents the aleatoric uncertainty at two granularity levels, (e.g. the input image can be annotated as either “2” or “3” and also has variations near boundaries.) and is trained by an Optimal-Transport-based loss function which minimizes the distance between the MoSE outputs and ground truth annotations.
Given an ambiguous image as input, our model consists of several expert networks and a gating network and produces segmentation samples with corresponding weights. It represents the aleatoric uncertainty at two granularity levels, (e.g. the input image can be annotated as either “2” or “3” and also has variations near boundaries.) and is trained by an Optimal-Transport-based loss function which minimizes the distance between the MoSE outputs and ground truth annotations.
Abstract
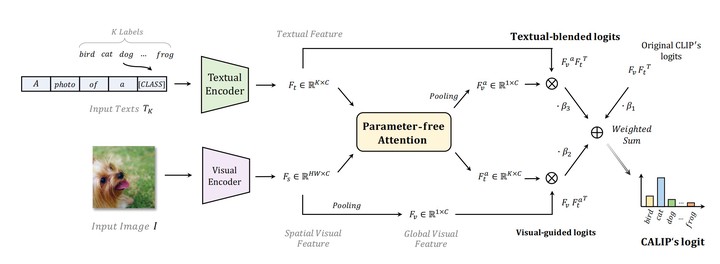
CALIP introduces a parameter-free Attention module to enhance CLIP’s zero-shot performance by enabling interactive cross-modal features using attention. It discards parameters due to reduced pre-training distances between modalities, achieving a training-free process. CALIP improves zero-shot performance over CLIP in various benchmarks for 2D image and 3D point cloud few-shot classification, and even with added linear layers, it outperforms existing methods under few-shot settings.
Type
Publication
In Proceedings of the AAAI Conference on Artificial Intelligence, 2023Proceedings of the AAAI Conference on Artificial Intelligence, 2023