Learning Multi-Granular Spatio-Temporal Graph Network for Skeleton-based Action Recognition
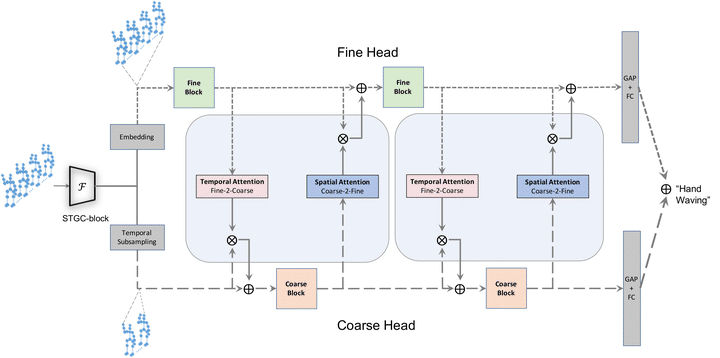 Model Overview
Model Overview
Abstract
The task of skeleton-based action recognition remains a core challenge in human-centred scene understanding due to the multiple granularities and large variation in human motion. Existing approaches typically employ a single neural representation for different motion patterns, which has difficulty in capturing fine-grained action classes given limited training data. To address the aforementioned problems, we propose a novel multi-granular spatio-temporal graph network for skeleton-based action classification that jointly models the coarse- and fine-grained skeleton motion patterns. To this end, we develop a dual-head graph network consisting of two interleaved branches, which enables us to extract features at two spatio-temporal resolutions in an effective and efficient manner. Moreover, our network utilises a cross-head communication strategy to mutually enhance the representations of both heads. We conducted extensive experiments on three large-scale datasets, namely NTU RGB+D 60, NTU RGB+D 120, and Kinetics-Skeleton, and achieves the state-of-the-art performance on all the benchmarks, which validates the effectiveness of our method.