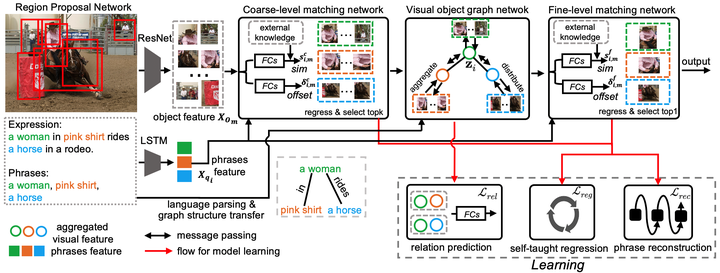
 Model Overview
Model Overview
Abstract
Visual grounding, which aims to build a correspondence between visual objects and their language entities, plays a key role in cross-modal scene understanding. One promising and scalable strategy for learning visual grounding is to utilize weak supervision from only image-caption pairs. Previous methods typically rely on matching query phrases directly to a precomputed, fixed object candidate pool, which leads to inaccurate localization and ambiguous matching due to lack of semantic relation constraints. In our paper, we propose a novel context-aware weakly-supervised learning method that incorporates coarse-to-fine object refinement and entity relation modeling into a two-stage deep network, capable of producing more accurate object representation and matching. To effectively train our network, we introduce a self-taught regression loss for the proposal locations and a classification loss based on parsed entity relations. Extensive experiments on two public benchmarks Flickr30K Entities and ReferItGame demonstrate the efficacy of our weakly grounding framework. The results show that we outperform the previous methods by a considerable margin, achieving 59.27% top-1 accuracy in Flickr30K Entities and 37.68% in the ReferItGame dataset respectively.
Yongfei Liu
Bytedance
My research interests include Cross-modal Reasoning, Scene Understanding, Commonsense Reasoning, few/low-shot learning
Xuming He
Associate Professor
My research interests include few/low-shot learning, graph neural networks and video understanding.