 Model Overview
Model Overview
Abstract
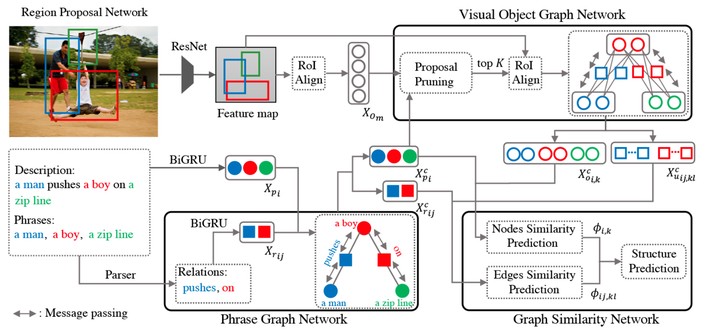
Visual grounding is a ubiquitous building block in many vision-language tasks and yet remains challenging due to large variations in visual and linguistic features of grounding entities, strong context effect and the resulting semantic ambiguities. Prior works typically focus on learning representations of individual phrases with limited context information. To address their limitations, this paper proposes a languageguided graph representation to capture the global context of grounding entities and their relations, and develop a crossmodal graph matching strategy for the multiple-phrase visual grounding task. In particular, we introduce a modular graph neural network to compute context-aware representations of phrases and object proposals respectively via message propagation, followed by a graph-based matching module to generate globally consistent localization of grounding phrases. We train the entire graph neural network jointly in a two-stage strategy and evaluate it on the Flickr30K Entities benchmark. Extensive experiments show that our method outperforms the prior state of the arts by a sizable margin, evidencing the efficacy of our grounding framework.
Yongfei Liu
Bytedance
My research interests include Cross-modal Reasoning, Scene Understanding, Commonsense Reasoning, few/low-shot learning
Xuming He
Associate Professor
My research interests include few/low-shot learning, graph neural networks and video understanding.