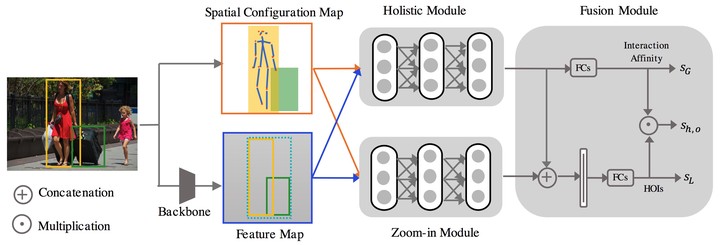
 Overview of our framework
Overview of our framework
Abstract
Reasoning human object interactions is a core problem in human-centric scene understanding and detecting such relations poses a unique challenge to vision systems due to large variations in human-object configurations, multiple co-occurring relation instances and subtle visual difference between relation categories. To address those challenges, we propose a multi-level relation detection strategy that utilizes human pose cues to capture global spatial configurations of relations and as an attention mechanism to dynamically zoom into relevant regions at human part level. Specifically, we develop a multi-branch deep network to learn a pose-augmented relation representation at three semantic levels, incorporating interaction context, object features and detailed semantic part cues. As a result, our approach is capable of generating robust predictions on fine-grained human object interactions with interpretable outputs. Extensive experimental evaluations on public benchmarks show that our model outperforms prior methods by a considerable margin, demonstrating its efficacy in handling complex scenes.
Yongfei Liu
Bytedance
My research interests include Cross-modal Reasoning, Scene Understanding, Commonsense Reasoning, few/low-shot learning
Rongjie Li
PhD Students
My research interests include scene understanding, deep learning, graph neural networks.
Xuming He
Associate Professor
My research interests include few/low-shot learning, graph neural networks and video understanding.