 Image credit: Qian He
Image credit: Qian He
Abstract
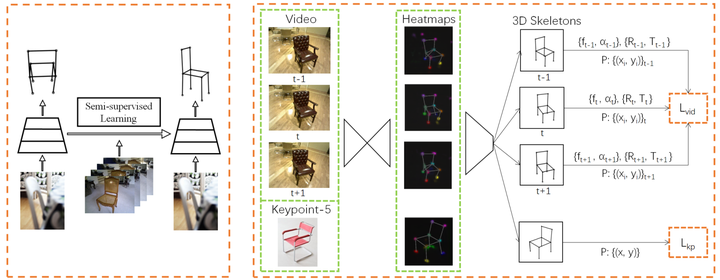
This paper addresses the problem of joint 3D object structure and camera pose estimation from a single RGB image. Existing approaches typically rely on both images with 2D keypoint annotations and 3D synthetic data to learn a deep network model due to difficulty in obtaining 3D annotations. However, the domain gap between the synthetic and image data usually leads to a 3D object interpretation model sensitive to the viewing angle, occlusion and background clutter in real images. In this work, we propose a semi-supervised learning strategy to build a robust 3D object interpreter, which exploits rich object videos for better generalization under large pose variations and noisy 2D keypoint estimation. The core design of our learning algorithm is a new loss function that enforces the temporal consistency constraint in the 3D predictions on videos. The experiment evaluation on the IKEA, PASCAL3D+ and our object video dataset shows that our approach achieves the state-of-the-art performance in structure and pose estimation.
Qian He
My research interests include single-view 3D reconstruction, 3D object representation, medical image segmentation and weak/semi-supervised learning.
Xuming He
Associate Professor
My research interests include few/low-shot learning, graph neural networks and video understanding.