Learning Dynamic Hierarchical Models for Anytime Scene Labeling
 Architecture of our IoU regressor.
Architecture of our IoU regressor.
Abstract
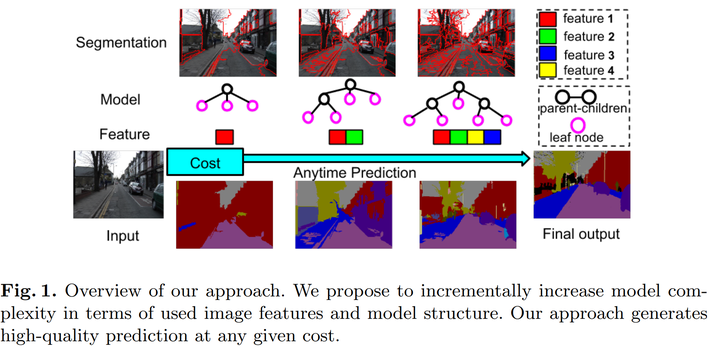
With increasing demand for efficient image and video analysis, test-time cost of scene parsing becomes critical for many large-scale or time-sensitive vision applications. We propose a dynamic hierarchical model for anytime scene labeling that allows us to achieve flexible trade-offs between efficiency and accuracy in pixel-level prediction. In particular, our approach incorporates the cost of feature computation and model inference, and optimizes the model performance for any given test-time budget by learning a sequence of image-adaptive hierarchical models. We formulate this anytime representation learning as a Markov Decision Process with a discrete-continuous state-action space. A high-quality policy of feature and model selection is learned based on an approximate policy iteration method with action proposal mechanism. We demonstrate the advantages of our dynamic non-myopic anytime scene parsing on three semantic segmentation datasets, which achieves 90% of the state-of-the-art performances by using 15% of their overall costs.