Building Scene Models by Completing and Hallucinating Depth and Semantics
 Architecture of our IoU regressor.
Architecture of our IoU regressor.
Abstract
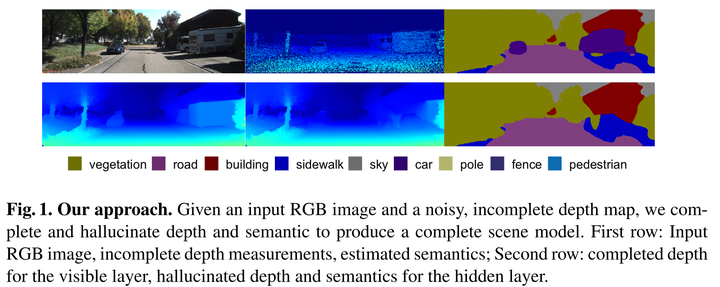
Building 3D scene models has been a longstanding goal of computer vision. The great progress in depth sensors brings us one step closer to achieving this in a single shot. However, depth sensors still produce imperfect measurements that are sparse and contain holes. While depth completion aims at tackling this issue, it ignores the fact that some regions of the scene are occluded by the foreground objects. Building a scene model would therefore require to hallucinate the depth behind these objects. In contrast with existing methods that either rely on manual input, or focus on the indoor scenario, we introduce a fully-automatic method to jointly complete and hallucinate depth and semantics in challenging outdoor scenes. To this end, we develop a two-layer model representing both the visible information and the hidden one. At the heart of our approach lies a formulation based on the Mumford-Shah functional, for which we derive an effctive optimization strategy. Our experiments evidence that our approach can accurately fill the large holes in the input depth maps, segment the different kinds of objects in the scene, and hallucinate the depth and semantics behind the foreground objects.